documentation:examples:forwarding_performance_lab_of_a_hp_proliant_dl360p_gen8_with_10-gigabit_with_10-gigabit_chelsio_t540-cr
- en
- fr
Table of Contents
Forwarding performance lab of a HP ProLiant DL360p Gen8 with 10-Gigabit Chelsio T540-CR
Forwarding performance lab of a quad cores Xeon 2.13GHz and quad-port 10-Gigabit Chelsio T540-CR
Bench lab
Hardware detail
This lab will test an HP ProLiant DL360p Gen8 with eight cores (Intel Xeon E5-2650 @ 2.60GHz), quad port Chelsio 10-Gigabit T540-CR and OPT SFP (SFP-10G-LR).
The lab is detailed here: Setting up a forwarding performance benchmark lab.
Diagram
+------------------------------------------+ +-------+ +------------------------------+ | Device under test | |Juniper| | Packet generator & receiver | | | | QFX | | | | cxl0: 198.18.0.10/24 |=| < |=| vcxl0: 198.18.0.108/24 | | 2001:2::10/64 | | | | 2001:2::108/64 | | (00:07:43:2e:e4:70) | | | | (00:07:43:2e:e5:92) | | | | | | | | cxl1: 198.19.0.10/24 |=| > |=| vcxl1: 198.19.0.108/24 | | 2001:2:0:8000::10/64 | | | | 2001:2:0:8000::108/64 | | (00:07:43:2e:e4:78) | +-------+ | (00:07:43:2e:e5:9a) | | | | | | static routes | | | | 192.18.0.0/16 => 198.18.0.108 | | | | 192.19.0.0/16 => 198.19.0.108 | | | | 2001:2::/49 => 2001:2::108 | | | | 2001:2:0:8000::/49 => 2001:2:0:8000::108 | | | | | | | | static arp and ndp | | /boot/loader.conf: | | 198.18.0.108 => 00:07:43:2e:e5:92 | | hw.cxgbe.num_vis=2 | | 2001:2::108 | | | | | | | | 198.19.0.108 => 00:07:43:2e:e5:9a | | | | 2001:2:0:8000::108 | | | +------------------------------------------+ +------------------------------+
The generator MUST generate lot's of smallest IP flows (multiple source/destination IP addresses and/or UDP src/dst port).
Here is an example for generating 5000 flows (different source IP * different destination IP) at line-rate by using 2 threads:
pkt-gen -N -f tx -w 2 -i vcxl0 -n 1000000000 -l 60 -4 -p 2 -S 00:07:43:2f:fe:b2 -s 198.18.10.1:2001-198.18.10.71 -D 00:07:43:2e:e4:70 -d 198.19.10.1:2001-198.19.10.70
And the same with IPv6 flows (minimum frame size of 62 here):
pkt-gen -N -f tx -w 2 -i vcxl0 -n 1000000000 -l 62 -6 -p 2 -S 00:07:43:2f:fe:b2 -s "[2001:2:0:10::1]-[2001:2:0:10::47]" -D 00:07:43:2e:e4:70 -d "[2001:2:0:8010::1]-[2001:2:0:8010::46]"
Netmap disable hardware checksum on the NIC, if you can't re-enable hardware checksum in netmap mode (like with Intel NIC), you need to use a FreeBSD -head with svn revision of 257758 minimum with thepkt-gen software-checksum patch for using multiple src/dst IP or port with netmap's pkt-gen. But this software checksum patch will reduce performance from line-rate to about 10Mpps.
Receiver will use this command:
pkt-gen -i vcxl1 -f rx -w 2
Configuration and tuning
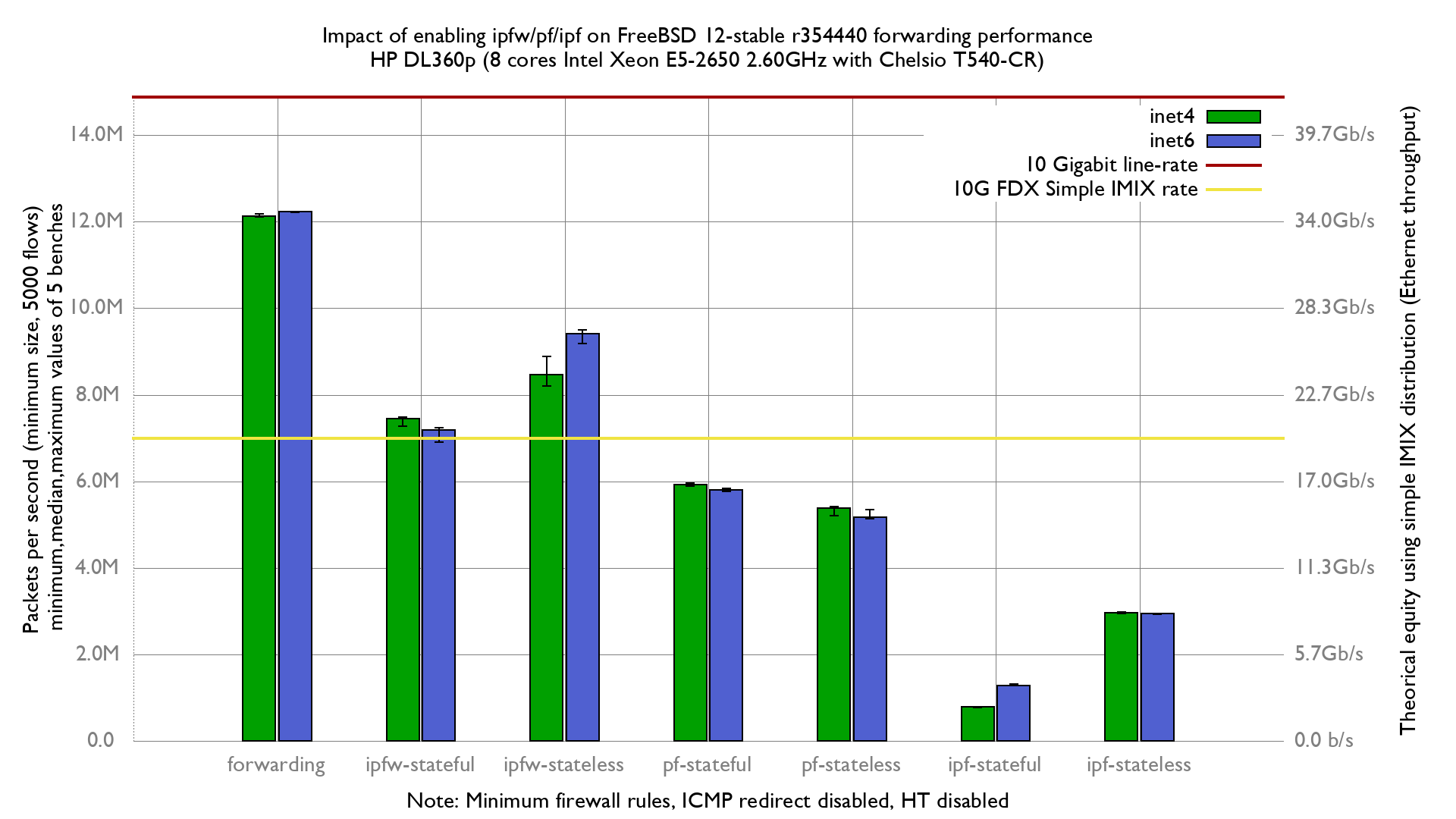
Results
documentation/examples/forwarding_performance_lab_of_a_hp_proliant_dl360p_gen8_with_10-gigabit_with_10-gigabit_chelsio_t540-cr.txt · Last modified: 2019/12/27 11:41 by olivier